Object Consistency - Girl Dance
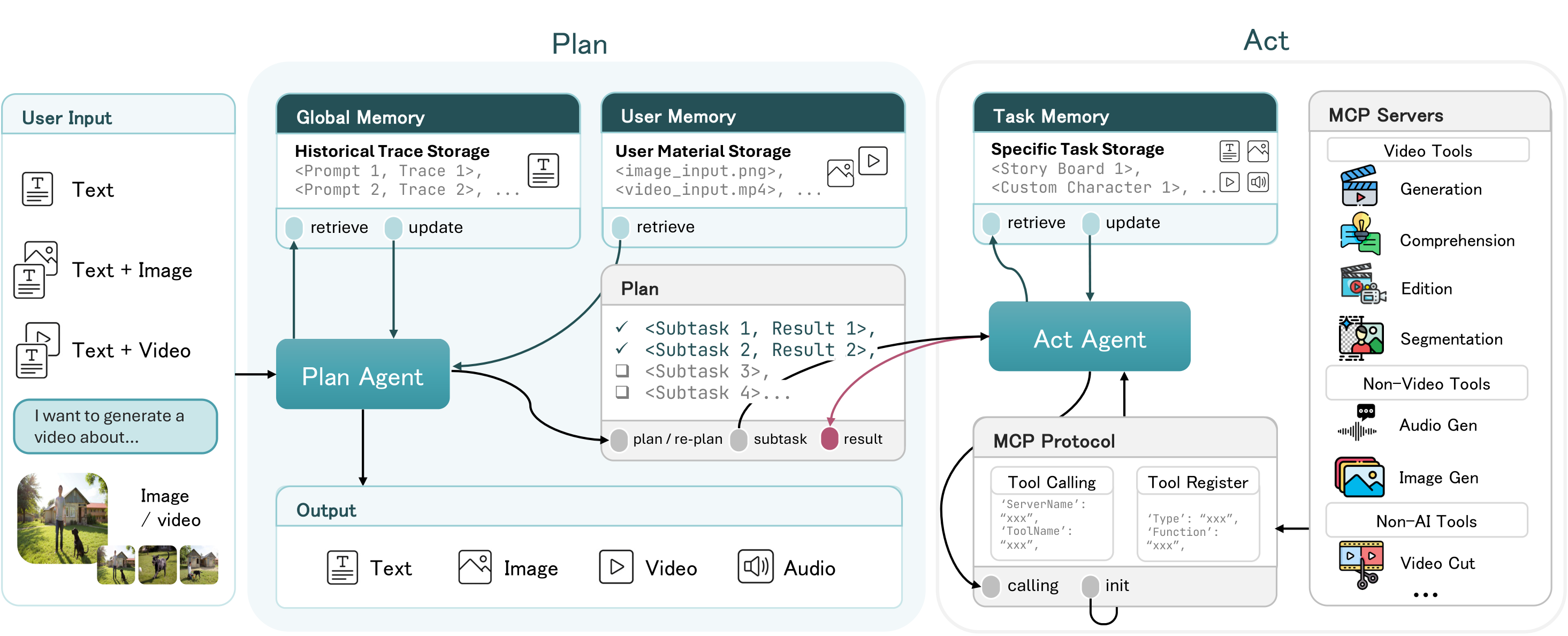
Input

I want a 20-second-long video with 4 segments. The main subject of the video is a girl dancing. However, the background of each of the 4 segments needs to be different. I need the first segment to be a cyberpunk background, the second segment to be an aesthetic ink dream, the third segment to be a retro film block, and the fourth segment to be an abstract geometric dynamic. The main subject of the four segments should be consistent and the movements should be coherent.
Output
Complex Generation - BreadTalk Ad
Input
Please create an advertisement based on the following product advertising requirements. 1. Kneading dough in hands, close-up shot, highlighting the texture of the dough. 2. Sprinkling cherry blossom petals on freshly baked bread, slow motion close-up. 3. Customers taste bread in the store and show satisfied smiles. 4. The brand logo appears, with the text: 'BreadTalk'.
Output
Complex Generation - Short Documentary
Input
Please generate a 30-second short documentary video based on the following story beats. 1. Close-up of clay meeting a spinning wheel; fingers press and a rib tool carves spirals as slip flicks outward under warm studio light. 2. Over-the-shoulder time-lapse: the vessel rises from cylinder to wide bowl; wet sheen glistens while the wheel slows. 3. Kiln-loading montage: shelves slide in, the door seals, orange heat blooms; a thermocouple readout climbs as a notebook of glaze formulas flips. 4. Slow-motion glaze pour coats the cooled bowl; cross-dissolve into a firing time-lapse where crystalline patterns emerge. 5. Morning reveal: final bowl on a wooden table beside steaming tea; the potter signs the foot and exhales in quiet satisfaction.
Output
Video2Video - Story Video
Input
Recreate a new video that mirrors the original's style—cinematic transitions, lighting, pacing, and tone—but tells the story of an elderly man reliving his youth through a dreamlike journey across time.
Output
Complex Generation - Mood Piece
Input
Please generate a 20-second mood piece based on the following sequence. 1. Macro close-up of raindrops striking a neon-lit puddle; ripples mirror street signage in shimmering bokeh. 2. Slow-motion silhouettes under translucent umbrellas traverse a zebra crossing while headlight trails streak past. 3. An elevated train thunders by; droplets bead and slide down a window as the interior sound softens to breath. 4. A cat shelters under an awning; a vendor hands a steaming paper cup to a passerby, vapor curling into mist. 5. Dawn edges in: clouds lift to a pastel sky, a final drip falls from a traffic light, and the city exhales.
Output
Video2Video - Prequel Story
Input
Create a prequel to the original video that introduces the backstory of the same characters, matching their look, voice, and animation style, but telling a different story that leads into the original events.
Output
Complex Generation - Professional Video
Input
Clip 1 (Morning Preparation): The man stands before a mirror and adjusts the collar of his grey overcoat, his eyes filled with confidence. Clip 2 (Focused at Work): The man is focused on his computer screen, his fingers typing swiftly on the keyboard. Clip 3 (Afternoon Meeting): In a bright meeting room, the man engages in a meeting, listening attentively. Clip 4 (End of the Day): At dusk, he closes his laptop, and looks out the window, with an expression of satisfaction and relief on his face.
Output
Video2Video - Style Transfer
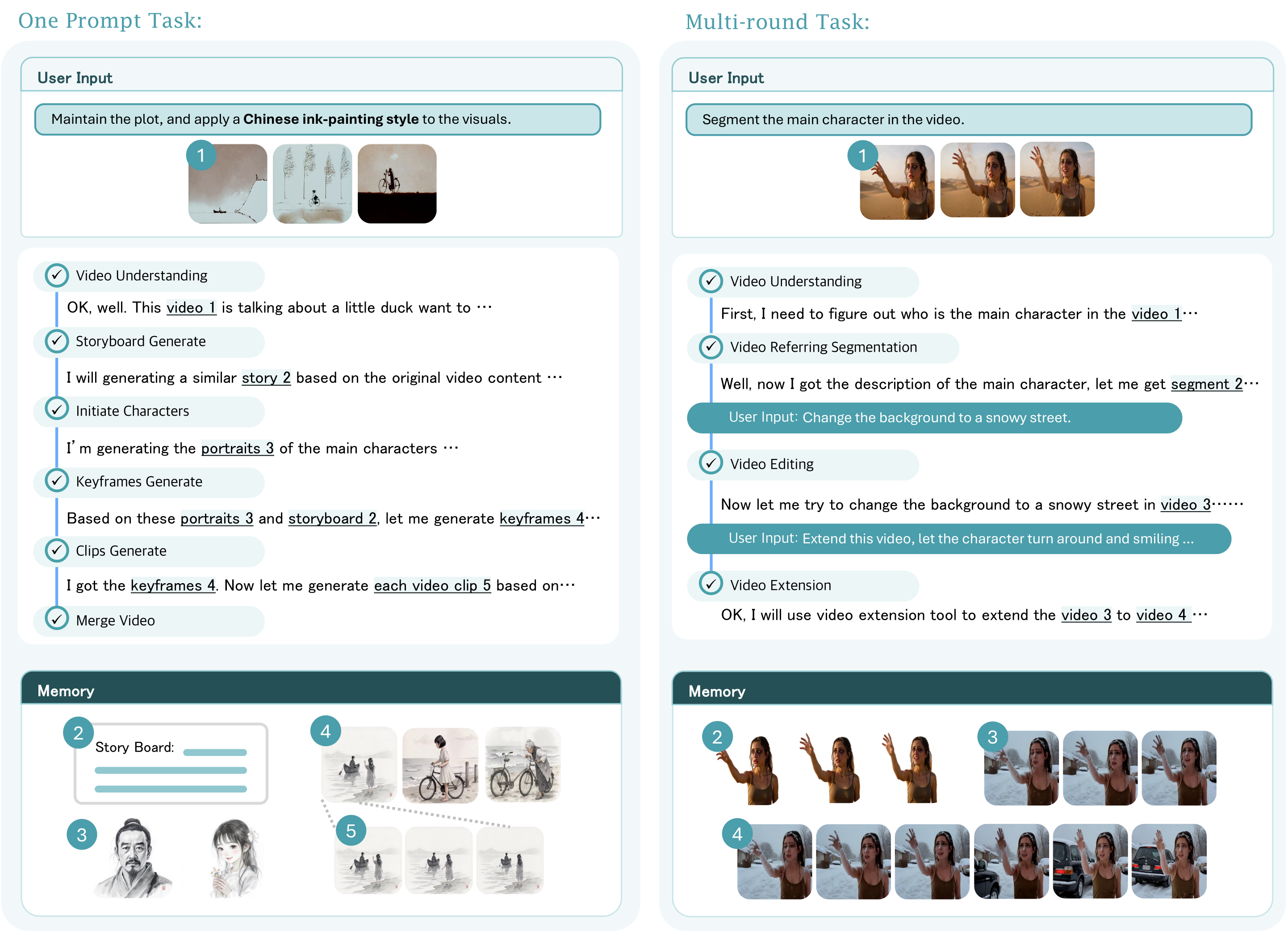
Input
Maintain all plot and motion as-is, and apply a Chinese ink-painting style to the visuals.